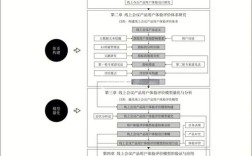
评价治疗性研究文章的框架
评价一篇治疗性研究文章,主要围绕以下几个核心问题展开:

(图片来源网络,侵删)
- 研究的结果是否真实可靠? (内部有效性)
- 研究结果有多大的临床意义? (效应量)
- 研究结果是否适用于我的患者或特定人群? (外部有效性/适用性)
下面我们分步详细解析。
第一步:评估研究的结果是否真实可靠?
这是评价的基础,旨在判断研究结果是否由研究本身的干预措施所导致,而非其他混杂因素。
研究设计是否为随机对照试验?
- 为什么重要? RCT是评估干预措施效果的金标准,随机分配可以确保干预组和对照组在已知和未知的基线特征上(如年龄、病情严重程度、合并症等)具有可比性,从而最大限度地减少选择偏倚。
- 如何评估?
- 是RCT吗? 文章中是否明确说明是“随机对照试验”或“randomized controlled trial”?
- 随机化方法是否描述? 好的研究会描述具体的随机化方法(如计算机-generated random numbers, 随机数字表),而不是简单地说“随机分配”。
随机化方案是否隐藏?
- 为什么重要? 如果研究人员在分配患者时知道下一个患者将被分到哪一组,他们可能会有意无意地选择符合或不符合纳入标准的患者,从而破坏随机化的作用,导致偏倚。
- 如何评估?
- 文章是否描述了分配隐藏的方法?使用中心随机系统、密封不透光的信封等。
- 如果没有提及或方法不恰当(如按入院顺序交替分配),则研究质量较低。
是否采用了盲法?
- 为什么重要? 盲法可以避免研究参与者(患者和医生/研究者)因知道分组情况而产生的心理和行为偏倚,从而影响结果的测量。
- 如何评估?
- 单盲? 只有患者不知道分组。
- 双盲? 患者、医生、研究人员、数据分析师等均不知道分组(这是理想状态)。
- 三盲? 在双盲基础上,负责统计分析的人员也不知道分组。
- 文章是否描述了设盲的具体对象和方法? 安慰剂外观是否与干预药物一致?对于无法设盲的干预(如手术),是否采用了终点评价者设盲?
是否对所有纳入的受试者进行了随访?
- 为什么重要? 失访会破坏随机化的平衡,如果干预组失访率高于对照组,且失访的原因与结局相关,可能会导致结果高估干预效果。
- 如何评估?
- 文章是否报告了每组有多少人开始研究,以及最终有多少人完成了研究?
- 意向性治疗分析 是否被采用?ITT原则是,无论患者是否中途退出或改变了治疗方案,都应将其分配到的原始组别进行分析,这是最保守、最能反映真实世界效果的分析方法,如果研究只完成了“符合方案分析”(Per-protocol analysis),且失访率较高,则结果可能不可靠。
各组除了干预措施外,是否接受了相同的治疗?
- 为什么重要? 如果对照组接受了额外的、可能有效的治疗,那么干预组与对照组的差异就会被缩小,可能得出“无效”的错误结论,反之,如果对照组接受了有害的治疗,则可能高估干预效果。
- 如何评估?
阅读研究方法部分,确认除了研究干预措施(如新药A)外,两组在其他所有方面的处理(如基础治疗、生活方式指导、随访频率等)是否完全一致。
研究的基线特征是否可比?
- 为什么重要? 这是随机化成功与否的“事后检验”,如果基线特征(如年龄、性别、疾病分期、关键指标等)在组间存在显著差异,说明随机化可能失败或存在未控制的混杂因素。
- 如何评估?
查看结果部分或附录中的“基线特征表”,比较干预组和对照组在各项基线指标上是否有统计学差异,P值>0.05被认为是可比的。
 (图片来源网络,侵删)
(图片来源网络,侵删)
第二步:评估研究结果有多大的临床意义?
如果研究结果是可靠的,下一步要看这个结果本身有多大价值。
结果是什么?
- 绝对风险降低: 这是最直观的指标。
对照组事件率 - 干预组事件率,对照组20%的患者发生心梗,干预组10%的患者发生心梗,则ARR = 10%。 - 相对危险度降低:
ARR / 对照组事件率,上例中 RRR = (20% - 10%) / 20% = 50%,听起来很厉害,但需要结合ARR来看。 - 需要治疗人数:
1 / ARR,这是衡量干预措施效率的极好指标,上例中 NNT = 1 / 0.10 = 10,意味着需要治疗10名患者,才能额外预防1例心梗事件,NNT越小,干预效果越好。
结果的精确度如何?
- 为什么重要? 研究结果只是一个点估计,存在抽样误差,置信区间能告诉我们这个真实结果可能落在哪个范围,以及这个估计有多精确。
- 如何评估?
- 关注95%置信区间,如果置信区间很窄,说明结果精确度高;如果很宽,说明结果不精确,可能样本量太小。
- 临床决策判断:
- 对于阳性结果(如干预有效),CI的下限是否具有临床意义?RRR为50%,但95%CI为1% - 99%,虽然结果“在统计学上显著”,但下限1%的临床意义很小,我们无法确定真实效果是否值得。
- 对于阴性结果(如干预无效),CI的上限是否排除了具有临床意义的效应?RRR为-5%(即无效),但95%CI为-15%到+5%,这意味着,干预无效,但也可能存在一个高达5%的益处(RRR=5%),这个5%的益处是否重要?如果临床上认为5%的益处是值得的,那么这个研究就不能得出“干预无效”的结论,只能说“研究未能证明其有效性”。
第三步:评估研究结果是否适用于我的患者?
即使研究再好,如果不能应用于实践,也意义不大。
我的患者与研究的受试者是否相似?
- 为什么重要? 这涉及到研究的外部有效性或普适性。
- 如何评估?
- 纳入/排除标准: 查看研究的纳入和排除标准,你的患者的年龄、性别、疾病类型、严重程度、合并症等是否符合这些标准?
- 基线特征: 将你患者的关键特征与研究中患者的基线特征进行比较。
- 研究地点: 研究是在单一中心还是多中心?是在教学医院还是社区医院?不同医疗环境下的结果可能不同。
干预措施在我的环境中是否可行?
- 为什么重要? 研究中的干预措施在现实世界中可能难以实施。
- 如何评估?
- 成本: 干预措施的费用是否可承受?
- 技术/资源: 是否需要特殊的设备、药物或专业人员?在我的医院/诊所能否获得?
- 患者依从性: 研究中的患者可能受到密切监督,依从性很好,我的患者能否长期坚持这种治疗方案?
利弊与风险如何权衡?
- 为什么重要? 任何治疗都有利有弊,需要综合评估。
- 如何评估?
- 益处: 研究显示的疗效有多大(结合NNT)?
- harms/风险: 研究中报告了哪些不良反应?发生率是多少?严重程度如何?
- 成本: 除了经济成本,还有时间成本、生活质量影响等。
- 共同决策: 将这些信息与你的患者沟通,尊重患者的价值观和偏好,共同做出决定。
快速评价清单
当你快速浏览一篇治疗性研究文章时,可以问自己这几个关键问题:
| 评价维度 | 关键问题 | 优质研究的标志 |
|---|---|---|
| 真实性 | 是随机对照试验吗? | 是,且随机化方法描述清楚。 |
| 分配方案隐藏了吗? | 是,且方法恰当。 | |
| 采用盲法了吗? | 是,尽可能设盲(双盲为佳)。 | |
| 随访完整吗?用了ITT分析吗? | 失访率低,且进行了意向性治疗分析。 | |
| 重要性 | 结果有多大? | 报告了ARR, RRR, NNT等临床重要指标。 |
| 结果精确吗? | 95%置信区间窄,且对于阳性/阴性结果有明确的临床意义。 | |
| 适用性 | 我的患者与研究对象相似吗? | 纳入/排除标准允许我的患者入组。 |
| 干预措施在我的环境可行吗? | 成本、技术、依从性均可接受。 | |
| 利弊权衡对患者有利吗? | 益处 > 风险和成本,并与患者价值观相符。 |
通过以上系统性的评价,你就能从一个“知识的消费者”转变为一个“循证的实践者”,科学、审慎地应用医学研究的结果。

(图片来源网络,侵删)