在访谈研究中,研究者常会遇到一系列问题,这些问题可能涉及研究设计、实施过程、数据分析及伦理规范等多个环节,若处理不当,可能影响研究的信度、效度及最终结论的可靠性,以下从不同阶段详细探讨访谈研究中常见的问题及应对思路。
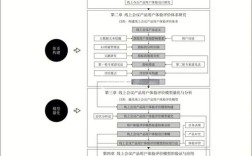
研究设计阶段的问题
研究设计是访谈研究的基础,此阶段的问题往往源于对研究主题的界定不清或对方法特性的理解偏差。
研究问题与访谈方法不匹配
访谈法适用于探索复杂现象、深入理解个体经验,但部分研究者误将其用于大规模量化问题的验证,研究“某政策对居民收入的影响幅度”时,若仅用访谈收集主观感受,可能因样本代表性不足导致结论偏颇,此时需明确:访谈适合回答“如何影响”“为何影响”等过程性问题,而非“影响多大”等量化问题。
访谈对象选择标准模糊
研究对象的选择需符合“信息丰富性”原则,但研究者易陷入“便利性抽样”误区,如仅选取身边易接触的群体,导致样本同质化,研究“农村留守儿童教育困境”时,若仅访谈村干部而忽略留守儿童、家长及教师,可能遗漏关键视角,应对策略是预先制定明确的纳入与排除标准,结合目的性抽样与滚雪球抽样,确保样本多样性。
访谈提纲设计缺乏逻辑性
部分研究者将访谈提纲设计为“封闭式问题清单”,限制了受访者表达;或问题跳跃性过大,缺乏逻辑过渡,直接询问“您对当前工作满意度如何?”而不先了解其工作内容、职责背景,受访者可能难以给出针对性回答,正确做法是采用“漏斗式”结构:从宽泛的开放性问题入手(如“您能描述一下一天的工作吗?”),逐步聚焦到核心议题,同时预留追问空间。
实施阶段的问题
访谈实施是数据收集的关键环节,此阶段的问题多与研究者沟通技巧、现场控制能力相关。
访谈关系建立困难
受访者可能因对研究目的不信任、性格内向或对敏感话题回避,导致访谈氛围紧张,研究“企业员工职场压力”时,若受访者担心回答影响工作,可能选择敷衍或隐瞒,研究者需通过“破冰技巧”(如分享自身相关经历、强调匿名性)建立信任,并采用“非评判性态度”,避免使用“您为什么会这样想”等暗示性语言。
提问方式不当导致信息偏差
研究者无意识的引导性提问可能扭曲受访者真实想法,问“您是否认为这项政策对您有益?”已隐含“政策有益”的预设,受访者易顺着研究者意图回答,应改为中性提问:“这项政策对您有哪些影响?”追问不足也是常见问题,当受访者提到“工作压力大”时,若不追问“具体体现在哪些方面”“这种压力持续了多久”,可能丢失关键细节。
访谈环境与记录干扰
嘈杂的环境(如咖啡馆、开放式办公室)可能分散受访者注意力;录音设备故障、笔记遗漏则会导致数据不完整,在户外访谈时突然出现的噪音可能打断受访者思路,影响回答质量,研究者需提前选择安静、私密的空间,并对录音设备进行测试,同时采用“录音+笔记”结合的方式,记录关键表情、动作等非语言信息。
数据分析阶段的问题
数据分析是将原始资料转化为研究结论的核心步骤,此阶段的问题主要涉及处理方法与主观性控制。
数据编码缺乏系统性
编码是访谈数据分析的基础,但研究者易陷入“主观编码”误区,即仅凭个人经验提取主题,忽略数据本身的逻辑,分析“老年人养老需求”访谈数据时,若研究者预设“医疗需求是核心”,可能忽略“精神陪伴”“社交活动”等其他重要主题,应对方法是采用“开放式编码-主轴编码-选择性编码”三级编码流程,先独立编码再与团队讨论,确保编码的客观性。
忽视受访者语境与个体差异
访谈资料是“语境化”数据,脱离具体语境的分析易导致误读,受访者说“工作太累了”,可能指“工作量过大”,也可能指“缺乏成就感”,需结合其工作背景、语气等判断,过度概括个体经验也可能存在问题,如将某位受访者的观点上升为“所有年轻人的普遍看法”,需通过“三角验证”(结合不同受访者、文献资料或数据)验证结论的普适性。
数据分析工具使用不当
部分研究者盲目追求软件(如NVivo、MAXQDA)的复杂功能,却忽略人工分析的重要性,仅依赖软件关键词统计,忽略语义差异(如“满意”与“基本满意”的区别),正确的做法是:先通过人工阅读把握整体脉络,再借助软件辅助编码与分类,同时保留“备忘录”记录分析过程中的思考与反思。
伦理规范阶段的问题
伦理是访谈研究的底线,此阶段的问题若处理不当,可能引发法律风险与信任危机。
知情同意流于形式
部分研究者仅让受访者签署简单的同意书,未详细说明研究目的、数据用途、保密措施及退出权利,研究“未成年人网络成瘾”时,若未告知家长访谈内容可能用于学校干预,可能侵犯未成年人隐私,知情同意过程需“透明化”,采用受访者易懂的语言解释研究细节,并允许其随时提问或退出。
数据保密与隐私保护不足
访谈资料(尤其是录音、笔记)若未妥善保管,可能导致受访者信息泄露,将访谈录音文件命名为“受访者姓名+电话”并存储在公共电脑,易被他人获取,研究者需对数据进行匿名化处理(如用编号代替姓名、模糊敏感信息),并采用加密存储、限制访问权限等措施,确保数据安全。
结果呈现中的伦理风险
在撰写研究报告时,若直接引用受访者原话且未做匿名化处理,可能使其身份被识别,在研究“职场性别歧视”时,引用某位女性受访者的具体经历并提及所在行业,可能对其造成负面影响,需对敏感信息进行“去标识化”处理,避免直接引用可能暴露身份的细节。
其他常见问题
样本量不足或过量
部分研究者因时间或资源限制,仅访谈5-8名受访者便急于下结论,可能导致“数据饱和”未达到(即新增数据不再提供新主题);也有研究者访谈数十人却未提炼核心观点,陷入“数据冗余”,判断样本量的标准是“信息饱和度”,即当新增访谈不再产生新主题时停止,通常质性研究样本量在12-20人之间较为适宜。
研究者主观偏见干扰
研究者的个人经历、价值观可能影响其对资料的解读,研究者若坚信“AI技术必然导致失业”,可能在分析访谈数据时选择性引用支持该观点的内容,忽略反驳性证据,需通过“反思性笔记”记录个人偏见,并邀请同行对分析结果进行 peer review,减少主观影响。
相关问答FAQs
问题1:访谈中遇到受访者沉默或不愿回答敏感问题时,如何处理?
解答:受访者沉默可能因紧张、思考或回避,此时可给予10-15秒的缓冲时间,用鼓励性语言(如“没关系,您可以慢慢想”)缓解压力,若涉及敏感话题(如收入、隐私),可先说明该信息的必要性及保密措施,或采用“间接提问法”(如“您身边大多数人收入水平如何?”代替“您收入多少?”),若受访者明确表示不愿回答,应尊重其选择,转向其他问题,避免强迫。
问题2:如何确保访谈数据分析的客观性?
解答:客观性可通过以下措施保障:① 采用“多人编码”,由2-3名研究者独立编码后对比差异,通过讨论达成共识;② 结合“三角验证法”,用不同来源的数据(如访谈、文献、观察记录)相互印证结论;③ 使用“成员检验”(Member Checking),将初步分析结果反馈给部分受访者,确认其是否符合原意;④ 区分“描述性结论”(基于受访者直接陈述)与“解释性结论”(研究者基于数据的推论),明确标注推论依据。